
テクノロジ系 > 大分類1 基礎理論 > 中分類2 アルゴリズムとプログラミング > 1.データ構造 > (2)データ構造の種類
データ構造には様々種類がありますが、応用情報技術者試験のシラバスでは配列、リスト、スタックとキュー、木構造の4種類が挙げられています。それぞれの特徴を押さえておく必要があります。
配列
配列は複数のデータを番号付きの複数の入れ物の中に順番に入れておいて管理するデータ構造です。複数の箱が横一列に連結されたものを思い浮かべると良いでしょう。
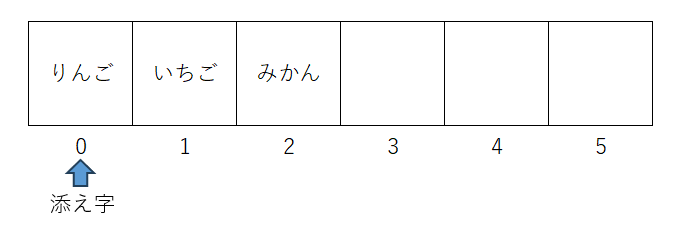
配列における番号のことを添え字といい、データを格納する1つのスペースのことやその中のデータのことを要素といいます。要素にアクセスする際に添え字を用います。
配列の仕様はプログラミング言語によって異なりますが、多くの言語では角括弧([])を用いて、[3,5,8]のように表されます。データには配列名[1]のように、角括弧内に添え字を書いてアクセスし、データを入れたり取り出したりします。添え字は0から始まることが多いです。
配列を宣言した際にあらかじめ配列の要素数を指定しておく配列のことを静的配列といいます。例えばC言語では int a[9]と宣言すると0~9までの10個の領域が確保され、それ以上の要素は格納できません。一方、宣言時に長さが決まっていない配列のことを動的配列といい、追加・削除をすることによって長さが変化します。プログラミング言語によって仕様が異なっており、静的配列・動的配列がどちらも実装されているプログラミング言語もあれば、JavaScriptのように動的配列しかないものもあります。
配列のデータの追加
配列はデータを追加するには追加した要素より後ろの要素を一つずつずらしていく必要があり、次に紹介するリストよりやや難しいです。そのためデータの追加はpushと呼ばれる動作のように後ろに追加するのが一般的です。
多次元配列
配列の要素の中にさらに配列を入れたものを多次元配列と言います。
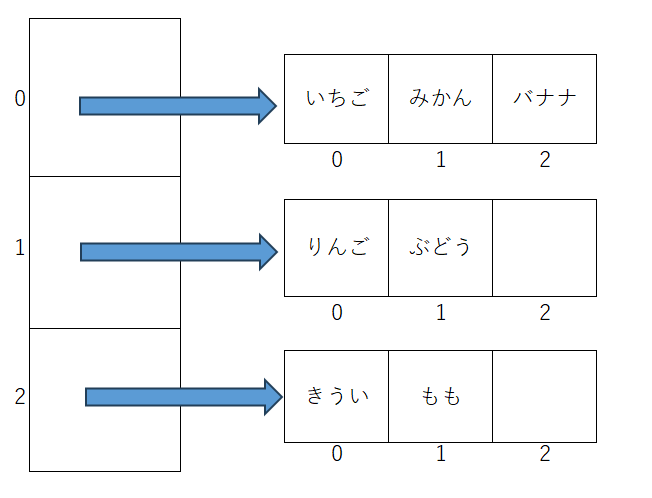
上の図のように、1次元目の配列には次の配列への参照が入ります。2次元目の配列の中にいちご、みかん、バナナなどの文字列のデータが格納されています。例えばみかんには、配列[0][1]のようにアクセスします。このような配列のことを2次元配列と呼びます。2次元目の配列にさらに次の配列の参照を入れることもでき、3次元、4次元とさらに深くしていくこともできます。出題されるのは2次元配列が多いため、2次元配列のデータへのアクセス方法を押さえておくとよいでしょう。
以上が配列の主なポイントです。配列はプログラミングにおいて重要な仕組みであり、数値や文字列を入れておいて、それをループ文で取り出して一つ一つ処理していくなど、効率的なプログラムを組みためにはなくてはならない存在です。
リスト
リストはデータとデータのつながりをポインタを使って指し示すようにする構造です。
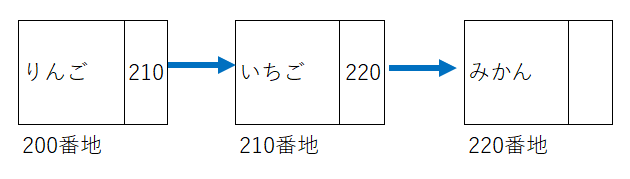
リストには次のデータだけを指し示す単方向リスト、次のデータに加え前のデータも指す両方向リスト、末尾と先頭が連結した環状リストがあります。
格納したデータにアクセスするためには、単方向リストの場合は前から順に探索していく必要があるため配列よりも遅いです。ただしデータを追加・削除するためにはポインタの値を書き換えるだけで済むため、配列よりも高速です。
配列とリスト
配列とリストは用途が似ているため混同されることが多く、配列のことをリストと呼ぶこともありややこしいです。
線形リストは一列にデータが並んだリスト構造で、配列によって実現することができます。ただし、「ポインタを用いた線形リスト」というような言い回しもあり、この場合はリストで説明した形式のデータ構造を指します。
リンク付きリスト(連結リスト)は次のデータへのリンクが付いたもので、ポインタ付きのリストはリンク付きリストということができます。
配列とリストは、データの取り出し方、追加・削除方法が異なるため、パフォーマンスが異なります。データへのアクセスは配列の方が高速で、データの追加・削除はリストの方が高速です。
また、静的配列の場合はあらかじめメモリ領域を確保する必要があるため、無駄な領域を確保してしまうことが多いのに対し、リストの場合はこのようなことが無いためメモリは効率的に使用できます。
スタックとキュー
スタックはデータを順に格納していき、取り出す時は最後に入れたものから取り出すものです。
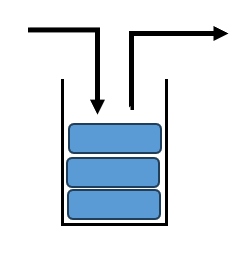
布団を押し入れにしまうとき、最後に重ねたものしか取り出せないのと同じ構造です。後入れ先出し(Last In First Out:LIFO)ともいいます。スタックにデータを入れる操作をpush、取り出す操作をpopと呼びます。スタックはプログラムの関数呼び出しなど、コンピュータの裏側で広く使われている仕組みです。
キューはデータを順に格納していき、取り出す時は最初に入れたものから取り出すものです。行列に並んだ時に先頭から案内されるのと同じ構造です。先入れ先出し(First In First Out:FIFO)ともいいます。キューにデータを入れる操作をenqueue、データを取り出す操作をdequeueといいます。
木構造
木構造はデータを階層的に管理するデータ構造です。階層構造にした形が枝分かれした木のようであることからこの呼ばれ方をします。
木構造の枝のように見える線は枝(ブランチ)、枝と枝の分かれ目に書く丸を節(ノード)といい、節が一つに集まる大元の部分を根(ルート)、その逆で先端の部分を葉(リーフ)といいます。
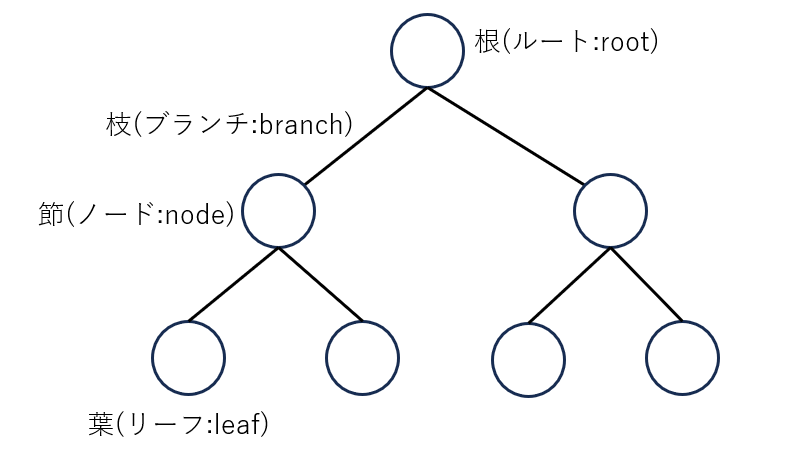
基本的には根を上に、葉を下に書きます。上から下に階層構造を表しており、上の節を親、下の節を子といいます。
一つの節から出る枝が0~2個の木構造を2分木といい、3個以上の枝が出る木構造を多分木といいます。ある階層にノードがすべて付くまで次の階層に進まない2分木を完全二分木とといいます。同様に、多分木の場合は完全多分木といいます。
木構造はそれぞれの節にデータを格納し、探索を行うことでデータの分析を行うために使います。
二分探索木
左側の子ノードの値が親ノードの値より小さく、右の子ノードの値が親ノードの値より大きくなるように値を格納した二分木のことを二分探索木といいます。データの大小関係は子孫にも及ぶように配置する必要があります。こうしておくことでデータの探索が簡単になります。
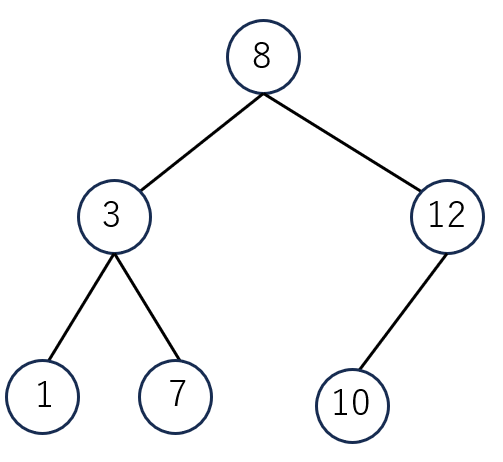
データの探索方法は根から始めます。上の二分探索木で7という数字を探すときに、8より小さいので左側の3へ、7は3より大きいので右側の7へ行き探索を終了させます。
二分探索木を完全二分木に変換し探索のための計算量を工夫するようにした構造をAVL木といいます。
二分探索木と似た構造で、親ノードの値がどの子ノード値よりも大きい構造をヒープといいます。
構文木
構文木は構文や文法などを木構造に格納したものをいいます。コンパイラが字句解析、構文解析などと呼ばれる解析をする際に使用します。
幅優先探索
木構造の探索方法には幅優先探索、深さ優先探索の2種類があります。
根から順番に、横向きに探索していく方法を幅優先探索といいます。
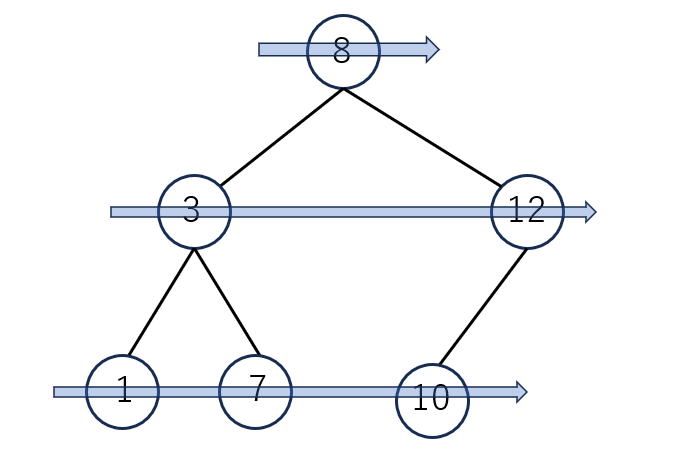
深さ優先探索
根をたどって部分木ごとに探索する方法を深さ優先探索と言います。親ノードから分かれた片方の木のひと固まりを部分木といいます。
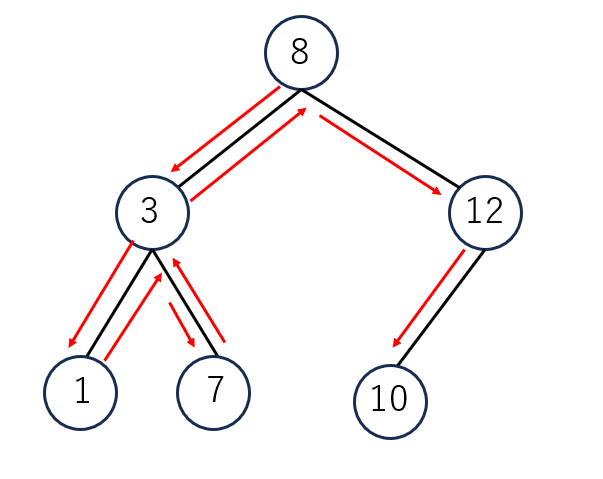
先行順(行きがけ順)は、ノードに初めてついた時に値を取り出します。上の図の場合、8,3,1,7,12,10の順で取り出されます。
後行順(帰りがけ順)は、部分木ごとに一番下の深さにたどり着いた時点で値を取り出します。すべて葉の値を取り出した後にノードの値を取り出していき、最後に根の値が取り出されます。上の図の場合、1,7,3,10,12,8の順で取り出されます。
中間順(通りがけ順)は、左の子に移動できなくなった時点で値を取り出します。上の図の場合は、1,3,7,8,10,12になります。
データ構造の種類のポイント
データ構造の種類には配列、リスト、スタックとキュー、木構造の5種類があることを覚えましょう。このうち配列とリストは用途が似ていて混同しやすいですが、それぞれ特徴があるため比較しながら覚えるとよいです。スタックとキューはシラバス上まとめられていますが、2つありそれぞれ特色があります。この二つはどっちがどっちだっけ?となりやすいので図と結びつけてしっかり覚えます。用語が多くて難しいのは木構造で、探索方法など深く覚えておく必要があります。
データ構造で配列とリストは実務のプログラミングでも多用するため必須の知識ですし、スタックとキューも普段使っているパソコンの裏側で動いている重要なものです。一見身近で簡単そうに見えるテーマですが出題の難易度は高く、深く内容を覚えていないと回答できない問題が出題されています。過去問の傾向をしっかり確認して、確実に解答できるようにしておきたいです。

